Storage paradigms
“Someone must have slandered Josef K., for one morning, without having done anything truly wrong, he was arrested.”
-- Franz Kafka, Der Prozess
A long long time ago, storage was conceptually a reasonably simpler matter. Of course, with the shortcomings of the computer technology that many decades ago, the hardware realization was anything but simple, but on the abstract theoretical level, things tended to be uncomplicated.
This was not because it would be an uncomplicated matter, but rather, in these primordial ages, no one had yet had the time to stop to think about it. For a long time, there wasn't as much pressure to do so anyway, as our computing system, and, hell, utilization of computers in different industries and applications remained limited.
Perhaps it was the horrors from serving in World War II, or inspiration from his trip to Canada, but at the dawn of the 1970s, Edgar "Ted" Codd decided to complicate our lives, leading us closer to proverbial salvation in the process. While working at IBM, Codd worked out his theories of data management, eventually issuing the infamous paper "A Relational Model of Data for large Shared Data Banks", coining the term (and inventing) relational databases, and opening the flood gates for further research into the topic of databases and data storage.
The paper is available freely online, if you wish to take a look: https://dl.acm.org/doi/pdf/10.1145/362384.362685
However, before we get to relational databases, let's examine a couple other models. While there exists quite many models, we shall only limit ourselves to ones that are most common and emblematic of different approaches and use cases of storing data.
Key - Value stores / databases
The simplest paradigm to reason about is the Key-Value paradigm. You have a set of keys, where every key is unique and points to some value. Perhaps the most well known and important example of a Key-Value (KV) database (also sometimes called KV store) is Redis.
KV stores typically have at least the two following commands for working with data:
set <k> <v>, which sets a value to a particular keyget <k>, which retrieves value associated with a key if it exists
In the case of Redis and Memcached, all the data is held in the machines memory, as opposed to most other databases that keep all their data on the disk. This has several implications. For one, the amount of data you can store is much more limited than disk-based databases, since you will typically have much less RAM than disk space and RAM doesn't scale up so well. On the other hand, however, this makes the database very fast, as RAM has much faster access speed, and queries may also be faster due to the database being conceptually extremely simple.
However, this means that you cannot execute any complex queries and if you want to work with your data in a more sophisticated way, you have to put in the proverbial leg-work yourself in your program. This may reduce efficiency and it complicates things for you as the end developer. To put it in other words, your data modeling options are very limited.
KV stores don't have a schema, and some don't even distinguish between types, which can complicate things for you if you do not know how the stored data is structured.
The KV storage pattern for entities is that we typically break them down into keys, and the identifier is typically a part of the key.
Imagine the following Rust structure:
#![allow(unused)] fn main() { struct Person { id: usize, name: String, age: usize, nationality: String, } }
In Redis, we could store the following instance:
#![allow(unused)] fn main() { let p = Person { id: 101, name: "Satoshi Nakamoto".into(), age: 69, nationality: "japanese".into() }; }
As such:
SET person:101:name "Satoshi Nakamoto"
SET person:101:age "69"
SET person:101:nationality "japanese"
This is better than doing something like SET person:101 <json of the Person instance>, as it makes
it easier to mutate the records (you don't have deserialize and reserialize just to increment age, for instance),
and it prevents you from being obligated to fetch all the data every time, even when you may be interested in
only one field.
The result of the aforementioned strengths and limitations is that KV stores are typically used for
things like caching, leaderboards, storage of temporary data and in the case of persistent KV stores,
they may also be used as the backing storage medium of a more complex database. A common example of this is RocksDB,
which may be the backend for Apache Cassandra, ArangoDB, MariaDB/MySQL, and FusionDB, which all differ
in what their storage paradigm is.
As you can see KV stores are quite flexible. Many of them also provide functionality for the Pub-Sub communication pattern, which we will discuss later.
Wide column databases
The previous paradigm one quite simple, one key, one value,. Wide column databases are quite similar to Key-Value databases, however, some structure has been introduced on the value side of things.
A wide column database is like if you took a KV store and added a second dimension to it. Keys are associated with column families, are each column family contains a set of ordered rows.
Let's take the previous Person example, and try storing it in Apache Cassandra:
INSERT INTO Person (id, name, age, nationality) VALUES ('101', 'Satoshi Nakamoto', '69', 'japanese');
The syntax used to store this data may look very similar to SQL, but in fact, it is not. The Cassandra Query Language cannot do joins or sub-queries, and other advanced things you might expect from SQL.
Wide column databases, similarly to KV stores, do not have a schema, and can therefore handle unstructured data. This makes them easier to set up, but contributes to the aforementioned issues.
On the other hand, wide column databases tend to be easier than relational databases to scale out and replicate across multiple nodes. In other words, wide column databases tend to be decentralized and scale horizontally.
Popular use cases of wide column databases include storing large amounts of time-series data (although there exist specialized time-series databases also!), historical records, and other use-cases, where you expect high amounts of writes, but low amounts of reads.
Apart from Apache Cassandra, other common implementations include Apache HBase and Apache Accumulo. Beyond Apache managed projects (as we will here a lot about Apache in these chapters), we might also include Scylla, which is essentially a C++ reimplementation of Apache Cassandra :)
Document databases
Wide column DBs are nice, but they typically will not be the main databases of your applications. For that, you need something that is more general purpose. In this domain, we may start with document-oriented databases.
In this paradigm, we have documents. Each document is a container of key-value pairs. They are unstructured, and also do not require a schema. The documents are grouped together in so called collections. Documents inside collections can be indexed, and collections can be organized into a logical hierarchy.
This allows you to model and retrieve relational-ish data to a significant degree. However, document-oriented databases still do not support joins, so instead of normalizing your data, you are encouraged to embed your data into a single document.
The downside is that while reads are typically fast and simple, but reading or updating records tends to be comparatively slower and more complex.
From a developer perspective, this database paradigm is very easy to used, and so it is found very commonly, especially in smartphone applications, games, content management systems, or applications for the Internet of Things. If you are not exactly sure how your data is structured, document databases might be a place to start.
Most commonly used document-oriented databases include MongoDB and Google's Firestore. An alternative for the proprietary Firestore is Apache CouchDB.
We can try storing the Person in CouchDB to illustrate:
curl -X PUT http://127.0.0.1:5984/my_database/101 -d '{ "name": "Satoshi Nakamoto", "age": "69", "nationality": "japanese"}'
CouchDB doesn't have a specialized query syntax, so we have to use the REST API.
Relational databases
Finally, huh :)
Document databases typically fall short where you have a lot of disconnected but related data, that is however updated often. Data like this has to be joined, and that is not easy to do in any of the aforementioned database paradigms.
Enter the relational database. This paradigm is the one you are most likely to be familiar using, as it has been around for more than fifty years, and it is the one that's commonly taught in schools and other software development courses.
The creation of relational databases inspired the development of SQL, which stands for Structured Query Language. It is a special type of a declarative programming language, called query language, that allows you to access and write data to the database.
Unlike the previously mentioned paradigms, relational databases have a schema, the data you store in them is structured, and if you want to alter the structure, you need to use special queries.
This less dynamic approach gave the way of the migration pattern, where you manage and in order apply the changes you make to your database in order to produce consistent state.
In Braiins, we store both the final schema and the migrations that lead to it, so that we can detect if there was a mismatch between them in the CI pipeline.
The concept of a document from document oriented databases is replaced with the concept of a relation, you can think of a relation as a table of rows and columns. Each row corresponds to one entry, each column corresponds to a particular piece of data we are tracking for each entry.
There is at least two special types of columns we must mention: primary key and foreign key. Primary keys are the IDs and main identifier of entries in each relation, whereas foreign keys are columns in one relation, that correspond to primary keys of another relation. These form relationships, and help facilitate joins, and subqueries.
This makes relational databases very versatile when modeling your data, and you can do a lot of your querying and "processing" work declaratively with SQL on the side of the database, which can be more handy for the developer, and also more effective, as less data has to be transferred.
Here is how you would store our Person in an SQL database:
INSERT INTO person (id, name, age, nationality) VALUES (101, "Satoshi Nakamoto", 69, "japanese");
However, we require a schema upfront, the table must be created:
CREATE TABLE `person` (
`id` INT,
`name` VARCHAR,
`age` INT,
`nationality` VARCHAR,
PRIMARY KEY (`id`)
);
Another thing to note about relational databases is that the most ubiquitous implementations are ones that are so-called ACID-compliant. ACID stands for Atomicity, Consistency, Isolation, and Durability.
These guarantees are related to transactions:
- Atomicity - If one part of a transaction doesn't work like it's supposed to, the rest will fail. In other words, either all of a transaction succeeds or none of it. It must be impossible for a transaction to produce an invalid state in the database, where only some changes we applied.
- Consistency - The database must follow the appropriate data validation rules. If a transaction occurs and results in data that do not follow the rules of the database, it must be rolled back to a previous state which does comply with the rules. On the other hand, if a transaction succeeds, and produces valid data, the data must be added to the database and the resulting state will be consistent with existing rules
- Isolation - This guarantees that all transactions will occur in isolation. This means that no transaction may affect another until it is completed. For example, if your transaction writes some data to the database, then another concurrently running transaction should be able to read said newly written data until the first one has completed.
- Durability - Data must be saved once a transaction is completed, even if a power outage or system failure occurs. If the database tells the connected client the transaction has succeeded, it must have, in fact, succeeded, and the data must be stored in persistent storage
ACID-compliance and the rest of the features of relational database make them harder to scale out. Although the situation has been improving in recent years, you are still more likely to struggle harder scaling out (horizontally) a relational database than any other of the previously mentioned paradigms.
Some of the most influential implementations are PostgresSQL and MySQL/MariaDB, and with a focus on horizontal scaling, CockroachDB.
As for applications, relational databases, in spite of their trade-offs, remain highly general purpose, and are used for all sorts of applications. However, they are not ideal for unstructured data.
Graph database
Let's go back a bit to the concept of a relationship from relational databases. What if we want a step further, and treated relationships as just another piece of data?
That let's us abstract ourselves all the way back to the concept of a graph, about which you were no doubt taught at school. In graph databases, data is represented as nodes and relationships between them are represented as edges. To retrieve the data you need for a particular use within your application, you just have to traverse the graph across the edges you need.
The mention of relationships with regards to primary and foreign keys in the previous section has been simplified, as we have not discussed how to do many-to-many relationships. In SQL databases, you would have to set up a join table, which tracks pairs of foreign keys between two relations to define the relationship.
In graph databases, we don't need such a table, we just define and edge and connect it to the other records. In addition, graph databases have pretty good performance, especially on larger datasets. These databases are slightly different to reason about (as we can no longer use the "thinking of things as a table" crutch), but they provide a formidable alternative to SQL databases, especially if your dataset makes sense to represent as a graph.
While there is not as many graph databases as there are for most of the previously mentioned paradigms, a number of them still exists and is used by big corporations.
Let's for example Redis Graph (because Redis, although originally a KV store ends up being able to do pretty much everything, including SQL, wide column and document), and see how it's used. To be able to leverage the graph, we need to complicate our example to include more than just a Person.
We will add another Rust type into the fray:
#![allow(unused)] fn main() { struct Car { id: usize, make: String, model: String, } }
Now we can define two relationships: people who drive the car and the person who owns the car.
CREATE (:Person { id: "101", name: "Satoshi Nakamoto", age: "69", nationality: "japanese" })->[:drives]->(:Car { id: "1", make: "Ford", model: "Mondeo"});
MATCH (c:Car) WHERE c.id = "1" CREATE (:Person { id: "102", name: "Ahti Mettälä", age: "39", nationality: "finnish"})->[:drives]->(c);
MATCH (c:Car) WHERE c.id = "1" CREATE (:Person { id: "103", name: "Lukáš Hozda", age: "21", nationality: "czech"})->[:drives]->(c);
MATCH (c:Car), (p:Person) WHERE c.id = "1", p.id = "Satoshi Nakamoto" CREATE (p)->[:owns]->(c);
In practice, we have to embed these queries in the GRAPH.QUERY <graph name> "<query>" statement.
We can visualize this data with a crappy online tool:
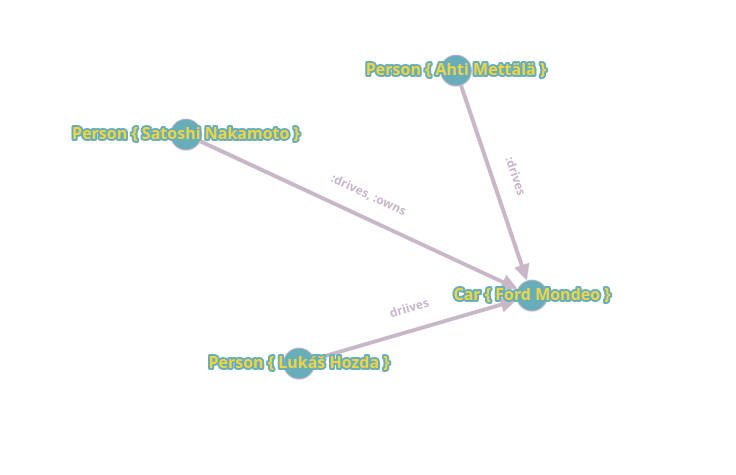
The most commonly used implementations are Neo4j, Apache AGE and ArangoDB. Their use cases include anything that can be modeled as a graph, such as knowledge graphs and recommendation engines.
Search Engines
But what if the most important functionality for you is the ability to search effectively and as fast as possible? That brings us to search engines, which are a type of database optimized for searching queries.
The basic functionality of a search engine is that for a small input text, the database must be able to return the most relevant search results as quickly as possible, and in a proper order, and we are typically searching through a huge amount of data.
Many of the databases in this domain are based on the Apache Lucene project, which has been around for over two decades. Well known search engines built on Lucene are for example Solr or Elasticsearch, from non-Lucene search engines, the french engine MeiliSearch which is written in Rust deserves a mention.
From your perspective as a developer, search engines are quite similar to document databases. You start with an index, and then you add a bunch of data to it. The difference from document databases lies in the fact, that under the hood, the engine analyzes your input and creates indexes of searchable terms.
When a user performs a search, the engine only has to search the index as opposed to completely searching through every contained document in the database. That makes it very fast, even on large datasets. The database can also run a number of algorithms to improve those results, such as ranking results, filtering out typos and accounting for linguistic features of a particular language to accommodate for things such as diacritics or declension.
This adds a lot of overhead and search engines can be quite expensive to run at scale, but at the same time they can add a ton of value to the user experience. Their most common usecases are building, well, search functionality into applications, log processing and analysis, and typeahead.
For example, to insert our original person into MeiliSearch, we would use cURL again:
curl -X POST 'http://localhost:7700/indexes/people/documents' -H 'Content-Type: text/csv' \
-D \
'id:number,name:string,age:number,nationality:string
101,Satoshi Nakamoto,69,japanese
'
(JSON and NDJSON are supported also, but would be longer to type out)
Log-based databases
In the previous chapter, we discussed transforming our mode of thinking from object to events. We can then log these events, producing a log that can be read sequentially, or seeked through by any number of readers.
This type of databases leans in to a stream-based mode of thinking, including switching from instant single queries to continuous queries. That helps us deliver results faster and prevent having to deal with long running and potentially time-expensive batch tasks.
Log-based databases are also typically geared towards horizontal scaling, which makes them more cost effective when your operations scale significantly. This also helps us with data safety, as we can choose how we want our data replicated, and the system does not lose data and keeps going on, even in case of node failures (to a certain extent, it is the same principle as RAID with drives).
The most ubiquitous and commonly used implementation of a log-based database Apache Kafka, which we use at Braiins too, and which is used by many big corporations in critical use cases. For a smaller scale example, we might look at Redis again, which has had the functionality also implemented for the last couple years.
However, as we shall see soon, their usecases differ.
Let's get more into how we deal with Kafka as a storage medium in the chapter.